Method Overview
The regularizer is required because trivial options such as training models with different initial weights, hyperparameters, architectures, or shuffling of the data do not prevent converging to very similar solutions affected by the simplicity bias.
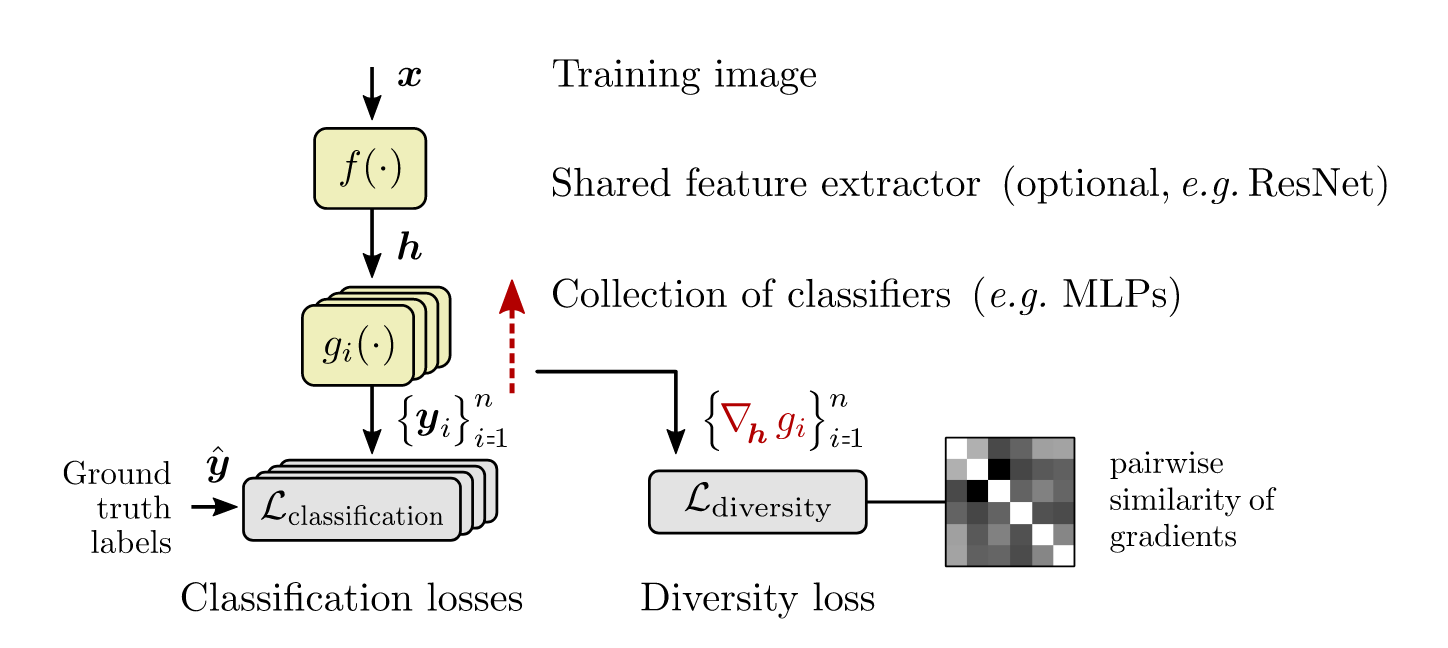
- A diversity loss penalizes pairwise similarities between models, using each classifier’s input gradient at training points.