AB Test¶
内容部分转载自:火山引擎文档 A/B实验科普
什么是AB Test¶
Note
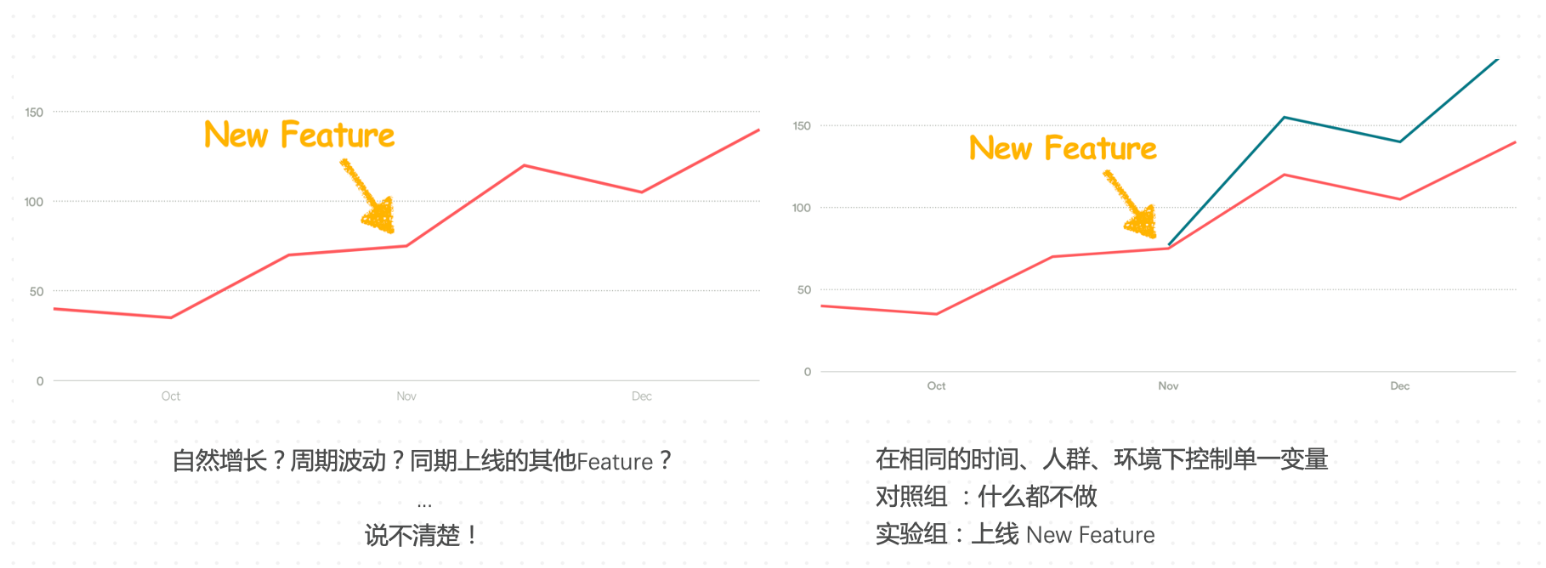
就是控制变量对照试验啦
A/B实验的基本思想就是:
我们在线上流量中取出一小部分(较低风险),完全随机地分给原策略A和新策略B(排除干扰),再结合一定的统计方法,得到对于两种策略相对效果的准确估计(量化结果)。 这一套基于小样本的实验方法同时满足了低风险,抗干扰和量化结果的要求,因此不论在互联网产品研发还是科学研究中,都被广泛使用。
为什么需要AB Test¶
Note
量化分析产品,数据驱动决策
如今,大多数互联网产品野蛮生长的时代已经过去,人口红利到顶,产品策略需要从快糙猛的跑马圈地方式转向深耕细作的精细化运营方式,要精细化运营,就需要采用数据来驱动。
何为数据驱动?试想以下几种场景:
- 小A凭着丰富的经验直接修改了产品的线上策略,一周后发现效果不升反降,遂下线。
- 小B和小C同时上线了两个产品功能,一周后产品数据有下降,都认为是对方的问题,谁也不肯接锅。
- 小D上线了一个新策略,随后进入十一黄金周,用户交互有所下降,小D觉得一定是假期埋没了自己的辛苦贡献,但也辩不明白,无处申冤。
- 小E辛苦工作一整年,开发了365个不同的功能上线,年终写总结时却写不出到底在哪些方面究竟贡献了多少。
想必不论是研发还是产品运营,都不希望自己辛苦工作过后落入上述的几种尴尬的境地中,因此数据驱动业务增长就显得很有必要。
那么数据变化和产品动作之间到底存在什么样的因果关系呢?
假设,某互联网公司承载了上百万规模的DAU,每天大量新特性等待上线,一方面业务人员无法承担其中任何一个错误特性直接影响用户体验的严重后果,另一方面业务人员又希望能够分离并量化每个特性的影响。
因此,我们需要设计并坚持使用一套数据驱动的方法,使得业务人员可以以较小的风险对新feature进行评估,积极试错积累经验;并且我们设计的该方法有能力排除其他因素(比如同时开发的其他feature以及时间因素等)的干扰;最后,除了“好”或者“不好”,我们希望这个方法最好也能够给出定量的结果。
为了解决上述问题,普遍使用的方法论是小流量随机实验,也就是我们常说的A/B实验。
如何开展AB Test¶
Note
AB Test实际上就是设计实验-->统计分析的过程。
实验的设计是为了最终的决策服务,例如探究产品的新feature能否带来用户增长。
统计分析就是假设检验,为决策提供理论支撑。
制定目标¶
对于任何一家 公司来说(不管是互联网公司还是传统公司),都有一个最重要的业务发展指标——“北极星指标“(North Star Metric),也称“唯一重要指标”(OMTM,One Metric That Matters)。 通常北极星指标需要包含四大特点:
- 能够反映产品为用户提供的 核心*价值;
- 能够衡量用户的 活跃*程度;
- 易于被团队理解;
- 能够反应企业整体上是否成功。
对于一些成熟行业,北极星指标已经相对固定,比如:
| 核心 价值 | 北极星指标 |
|---|---|
| 为用户提供物有所值的商品和互动式购物体验 | GMV(商品交易总额) |
| 让用户高效地获得值得信赖的答案 | 问题回答数 |
| 为用户提供高 品质 居住产品与生活服务 | 订单数 |
显然,北极星指标的制定是 企业 更为战略层面的工作,然而A/B测试不能绕开这一环。在北极星目标明确的前提下, 企业 才能通过系统化的A/B实验实现快速迭代和增长。
确定了北极星目标,各个业务团队需要分领属于自己的任务,这里便涉及到将北极星指标拆解为可执行的具体指标。拿电商平台做个例子,假如我设定2019年的GMV是300万美元,那么我们可以将这个北极星目标逐步拆解,例如:
在北极星指标被细化后,各个部门便可以围绕细化后的具体指标,开展有针对性的实验。
建立假设¶
在明确目标之后,增长团队应该着手分析早期数据,并从数据中找到增长的可能。这一过程需要产品经理、运营经理和技术研发共同探讨完成。 分析结束后,团队需要提出假设,如:将购买页面主色调从蓝色改为红色能够将用户购买率提升3%。
值得注意的是,我们所做出的假设必须包含两方面:
- 第一是 提出新策略 ,“购买页面主色调从蓝色改为红色”,这决定了实验中我们要如何配置实验参数;
- 第二是 确切的提升值 ,如“用户购买率提升3%”,这决定了应该有多少用户进入实验。
在A/B实验中,用指标的“预期值提升值”倒推实验流量(也就是样本量的确定),需要运用到复杂的统计学知识。
然而,即使你并不了解这些知识,使用成熟的A/B实验工具——火山引擎A/B测试的“实验流量建议工具”这一功能,就可以轻松确定应进入实验的流量。
配置实验¶
有几个关键的问题:
- Where 实验开在哪?
- 可以做分层抽样,把总体划分为同分布的几个流量层,这样就可以同时进行多个实验,互不干扰
- When 实验开多久?
- 基于一些统计学原理,实验开设得过长或过短都不利于实验结果的可信度。通常实验时长要与产品的“数据特征周期”一致。如何理解呢?比如某 直播 类app产品,用户在周一到周五的 活跃 度较低,在周末 活跃 度较高,以一个自然周为周期,不断循环。那么这一 直播 产品在做A/B实验时,通常应该将时长设置为一周。
- Who 谁进入实验?
- 实验中,我们要对进入实验的流量大小做出设置。通常在实验的初始阶段,我们倾向于先分配较少的流量(如1%)进入实验。如果初期实验结果一切正常,那么可以进一步加大流量;假如实验数据出现巨大的异常,那么可以随时将实验终止。小流量可以最低程度减少实验异常对用户体验的影响。
- 除了对流量大小进行设置之外,我们还可以添加限制条件,对进入实验的用户进行过滤,比如只看“安卓用户”、只看“北京地区用户”等等。这部分过滤条件通常需要由实验发起者和分析师共同确认。
- Metric 关注的指标?
- 确定哪些指标是我们所关注的。再来看看前文中我们做出的假设:将购买页面主色调从蓝色改为红色能够将用户购买率提升3%。在这一实验中,“用户购买率”必定是我们的关注的指标,并且是我们的“ 目标指标 ”。除此之外,我们还应该关注一些产品常关注的重要数据指标,用以 观察 实验中的新策略是否会对其他重要指标产生负面影响。
评估结果¶
实验结果需要从两方面评估:
- 第一是数据结果的涨跌;
- 第二是判断是否可以相信数据结果,即结果是否“显著”。
数据的涨跌自不必多言,如何理解数据是否显著呢?
我们知道,A/B实验是一种小流量实验,我们需要从总体流量中抽取一定量的样本来验证新策略是否有效。抽样过程中,样本并不能完全代表整体。样本分布不均导致实验结果可能出现一种情况——我采取的策略其实没用,但是实验结果显示策略有效。
统计学告诉我们,这种错误不可能完全避免,但是我们可以通过一些统计学方法,在得出实验数据结果的过程中,计算上述错误发生的概率。换句话说,我们可以判断我们的实验有百分之多少的概率是可信的。
根据业界的公认标准,在A/B实验中,如经统计学计算,实验数据结果有95%以上的概率可信,我们便称数据结果是显著的。这样的数据结果才能够用于判断实验假设是否成立。
Created: 2025-01-15 22:47:22